V souvislosti s umělou inteligencí se často hovoří o tom, kdo by se měl obávat o svou práci. Samozřejmě hned na první pohled je jasné, že je to každý, kdo nějak pracuje s textem, ale jisti si nemohou ani fotografové, stejně tak široké možnosti se brzy otevřou ohledně generování videa. Jeden zajímavý příklad ukazuje i projekt Animate Anyone.
Novou techniku generativního videa vyvinuli výzkumníci z Institutu pro inteligentní výpočetní techniku společnosti Alibaba Group. Je to velký krok vpřed oproti předchozím systémům pro převod obrazu na video, jako byly DisCo a DreamPose, které byly působivé v létě, ale dnes jsou již dávnou historií.
To, co Animate Anyone umí, není v žádném případě bezprecedentní, ale pokud se nedíváte pozorně, rozdílu si nevšimnete. Model převodu obrazu na video začíne extrakcí detailů, jako jsou rysy obličeje, vzory a póza, z referenčního obrazu, například z módní fotografie modelky v šatech na prodej. Poté se vytvoří série snímků, kde se tyto detaily mapují na velmi mírně odlišné pózy, které mohou být zachyceny nebo extrahovány z jiného videa.
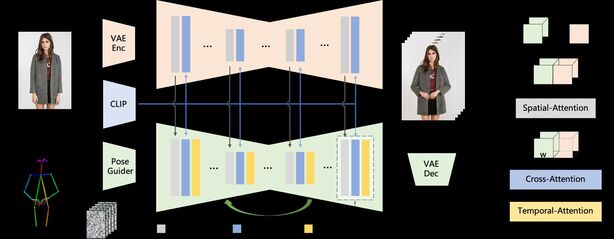
U předchozích modelů se vždy narazilo na problém, že AI nebyla schopna věrohodně odhadnout některé pro ni neznámé rysy, například pohyb dlouhých vlasů nebo volného oblečení. V takových případech si AI „vymýšlela“ detaily, což často vedlo k velmi zajímavým, ale nevěrohodným výsledkům. Nový krok však Animate Anyone umožňuje modelu komplexně se naučit vztah s referenčním obrazem v konzistentním prostoru rysů, což významně přispívá ke zlepšení zachování detailů vzhledu. Zlepšením zachování základních a jemných detailů mají generované obrazy v dalším kroku silnější podklady pro práci a dopadají mnohem lépe.

Tým podle svého vyjádření ještě ladí poslední detaily před tím, než se zdrojový kód a další náležitosti vypustí mezi běžné uživatele. Brzy se tak může stát, že TikTok bude zaplaven neexistujícími tančícími bytostmi. Sázka na to, že zde uděláte kariéru, tak bude brzy o hodně více nejistá, než je nyní.